browserrecon project advanced web browser fingerprinting |
| Introduction | News | Scan | Download | Documentation | FAQ | Database | Contact |
 Introduction Most of todays tools for fingerprinting are focusing on server-side services. Well-known and widely-accepted implementations of such utilities are available for http web services, smtp mail server, ftp servers and even telnet daemons. Of course, many attack scenarios are focusing on server-side attacks. Client-based attacks, especially targeting web clients, are becoming more and more popular. Browser-targeted attacks, drive-by pharming and web-based phishing provide a broad aspect of threats during surfing in the world wide web. Attacker might initialize and optimize their attacks by fingerprinting the target application to find the best possible way to compromise the client. The browserrecon project is going to prove, that client-side fingerprinting is possible and useful too. In this particular implementation, currently available in php only, the given web browser is identified by the used http requests. Similar to the http fingerprinting provided within httprecon (http://www.computec.ch/projekte/httprecon/) the header lines and values are analyzed and compared to a fingerprint database. The current implementation of browserrecon is provided as a php script and ready for live testing on the project web site. However, all web-based scripting languages that are able to access the http headers sent by the client are able to provide the same functionality. A port for classic ASP (Active Server Pages) is available. Further ports to ASP.NET, JSP and traditional CGI are possible. Even the web server itself or an inline device (e.g. a sniffer or a firewall) might be able to do the same fingerprinting of the http request behavior. A very similar approach for client-side application fingerprinting can be applied to other services and clients too. For example mail clients can be identified by their individual smtp and pop3 command chains. Or ftp clients might be determined by their specific command sequences. Architecture The application works very straight forward. Whenever the given http headers are sent to browserrecon for analysis, the identification process starts. These could be dissected to identify some specific fingerprint elements. Those elements are looked up in the local fingerprint database. If there is a match, the according implementation is flagged as "identified". All these flags were counted so browserrecon is able to determine which implementation has the best match rate. 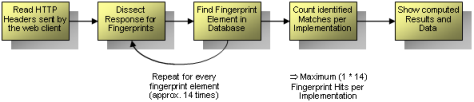 The following picture illustrates the architecture of the whole framework. The analysis engine might be able to analyze different http request methods (e.g. GET, POST and PUT). In the current release only HTTP GET requests are fingerprinted. 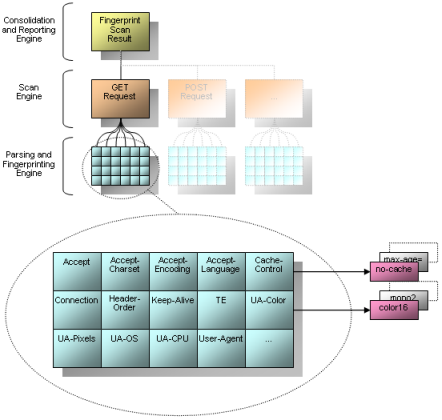 The dissection of the responses is handled by the parsing and fingerprint engine. As you can see many different fingerprint elements are looked up (e.g. accept, accept-language, user-agent, etc.). These elements are saved in the local fingerprint database which allows the sum of the matches. All data is correlated which will result in the final fingerprint scan report. Features These are the main features of the current implementation of browserrecon which makes this solution better than similar approaches and tools:
Installation browserrecon is an open-source suite which was developed for passive web browser fingerprinting. The basic idea is that the scripts are running in the background of a given web application to gather the implementation details by the clients. This process is not depending on the User-Agent information, which might be forged, only. The initial release of browserrecon is written in PHP. Therefore, you might be able to use browserrecon on a web server supporting PHP. If you want to include browserrecon in a given web application, the software has to support PHP itself or a fork of the PHP scripts. Because browserrecon requires direct access to the http headers sent to the web server, the framework is not able to run in PHP CGI mode. You have to copy the scripts of browserrecon to your web server. For example you might extract the downloaded archive into the directory /browserrecon. Afterwards you have to include the scripts. In PHP you can use the following call:
Afterwards you are able to access all functions of browserrecon within your application. To run an analysis of the client while he was accessing the site you can use the following call:
This will initiate the fingerprinting of the client regarding the headers sent for requesting the given web document. Afterwards the result of the analysis is echoed. In this case you are able to show your visitors that you are able to determine their client software accurately. The current headers of the clients http request are collected within the function getfullheaders() and sent to the main function browserrecon(). You might also be able to do an offline analysis by providing the header data within a form. Thus, a call like this one might be required:
However, you might be interested in further processing of the returned string data without displaying the results to your visitors directly. The following code block is able to redirect users according to their web browsers:
Divide and Conquer During the analysis of the different fingerprints some very clear aspects could be found to divide the major web clients. Those, they allow the identification of an implementation very quickly, shall now be discussed in detail. * Microsoft Internet Explorer The accept headers always begin with "image/gif" and do include "image/x-xbitmap" for Microsofts bmp images. Furthermore the extensions of Microsoft Office are included by default too (e.g. "application/vnd.ms-excel" for Word documents). The objects of the accept-encoding are delimited by a comma. Microsoft Internet Explorer is the only browser branch which also uses a space after the comma for the listing. The ua-headers were introduced by Microsoft with Internet Explorer 7.0 If one of them (ua-cpu, ua-os, ua-colors, ua-pixels) is used, you can tell which Internet Explorer version might be used. It seems like the current releases use "ua-cpu" only (e.g. x86 or AMD64).
* Mozilla Firefox Most browsers do use a first letter capitalized "Keep-Alive" within the connection line. Mozilla Firefox uses the only implementation with a small "keep-alive" all the time. The clients of the Mozilla project usually involve a Keep-Alive value of 300. Such a value can never be found while using a Microsoft Internet Explorer.
* Opera Most browsers do announce their preferred charset with a capitalized "ISO-8859-1". However, Opera is using a lower-case announcement of the form "iso-8859-1" within the accept-charset header. This only affects the ISO letters, no further encoding details (e.g. utf-8 is written non-capitalized only). Opera has usually the characteristic announcement of utf-8 and utf-16. The expected language defined in accept-language is usually written in small letters (e.g. de-ch for german/swiss). Opera is the only browser capitalizing the second definition (e.g. de-CH). And Opera is one of the few browsers which usually includes a te line.
* Netscape Navigator The Netscape Navigator introduced the support for png images around 4.x. In the older versions of 3.x the accept line shows "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*". Later we can see the enhanced version including png: "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/png, */*". Furthermore, old Navigators 3.x did not announce the language of the operating system within the user-agent line. Within the 4.x series the language was written surrounded by brackets like [en] for english. The current release 9.x use the common syntax en-US as a remark.
* Lynx Typical for Lynx, the classic line-based web browser for Linux, is the first Host line as it is common with Mozilla Firefox. The difference is, that the Accept-Encoding always supports gzip and compress, where as space follows the comma. Furthermore, in the accept line you are usually able to find application/x-debian-package for deb packages of Debian GNU/Linux.
(The diagrams on this web site are available for download here.) |
| © 2008-2024 by Marc Ruef |