codEX Project Normalizing as the first step to improve |
| Introduction | News | Documentation | Download | Contact |
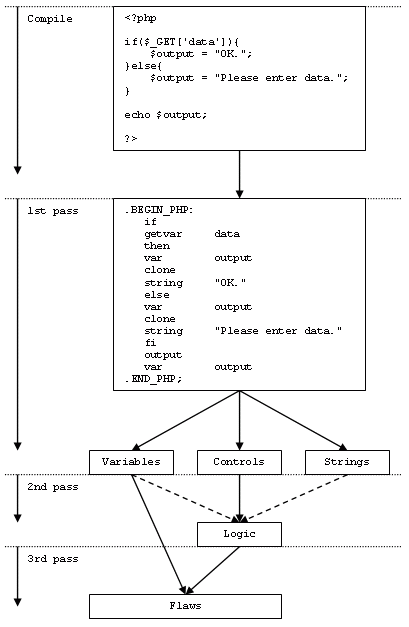 Lexer and Compiler Lexer and CompilercodEX is using different steps to do the source code analysis. In the first one an intermediate representation of the original source code is produced. This is realized with a language dependent lexer which produces language independend MetaCode™. It is a serialized form of the original program which looks like assembly language, which is the base for all further analysis and logical deduction. The major advantage of this remodelling with virtual compilation is the fact, that the analysis procedure is not depending on the original programming language anymore. The next steps do not care if the initial source code was ANSI C, PHP or Java. 1st Pass: Token Identification and Analysis In the second step the first pass of the code analysis is done. The normalized and reduced MetaCode™ is dissected and the different tokens identified. For example controls, variables and strings are isolated and their attributes (e.g. type, length, context) documented. It is very important to divide the tokens into different object classes. For example input string variables come with completely other attack vectors than internal integer variables. This makes it possible to handle them appropriate (e.g. static strings are not attack vectors in a first place). Furthermore, a virtual addressing is used which is going to be important for identification and data flow analysis. 2nd Pass: Logical Decisions and Data Flow The third step is defined as the second pass which is responsible for further analysis of code interaction and logic. Especially the statements of the control elements are analyzed which makes it possible to do a control flow diagram (CFD). This makes it possible to see the behavior of the application. Code blocks which are depending on some decisions and statements can be identified and therefore the logical sequence of program runs determined. 3rd Pass: Vulnerability Identification The fourth and final step is correlating all the data and identifying potential flaws and vulnerabilities. For example the use of not sanitized input data might be exploitable within an injection attack. Depending on which procedures and functions are used, the vulnerability class (e.g. SQL injection, cross site scripting, OS command injection) can be determined. |