codEX Project Normalizing as the first step to improve |
| Introduction | News | Documentation | Download | Contact |
| Lexer and Compiler The goal of a codEX analysis is to find vulnerabilities within the original source code. To do this in an appropriate way and with a language independency a parsing and reduction of the source is required [Holzmann 2003]. The result of this pre-compilation is intermediate code named as MetaCode™. A language dependend lexer is used to identify all the tokens of the used programming language. The language definiton is written as EBNF (Extended BackusNaur Form) and therefore new languages added very quickly [Knuth 1964]. The implementation of the lexer and compiler is realized with a straight pointer mechanism (metacode_pointer). The original source code is fed byte by byte into a string (metacode_chunk). On every iteration the lexer is looking for some known keywords which indicate a valid language token. If such a token (metacode_token) is detected, further dissection of the according component is started. For example if a control structure is found, the decision statement is separated and dissected too. After doing this another incrementation of the token pointer is done and the next iteration started. [Aho et al. 1986]
Very important for all the source code analysis are the variables. These bring up the dynamic of the application. Especially variables which are in contact with the user, no matter if input or output, are possible and mighty attack vectors. The identification of variables within PHP is solved by identifying the dollar sign ($). Every token that begins with this symbol is a potential variable. Then the regarding charset within the variable name is tested. If the second character is not an underline (_), the end of the variable name is determined. This data is rewritten to MetaCode™ with the following statement:
If the second character is an underline, it seems like a pre-defined variable of PHP. Four different of them can be identified by association (GET, POST, COOKIE, SERVER) and name. The conversion to regular MetaCode™ looks like this:
Also the strings, which are constant, are determined. Usually programming languages support two different identifiers to indicate such a string. The double quote (") and single quote (') are used for this within PHP and similar implementations. The lexer is searching such symbol which indicates the beginning of a string. Then it pushes forward to the next occurence of the same character to identify the end of the string. The string itself is presaved for further analysis:
The following diagram illustrates the process of token identification. In this case the begin and and of the string is detected to identify the string value itself. 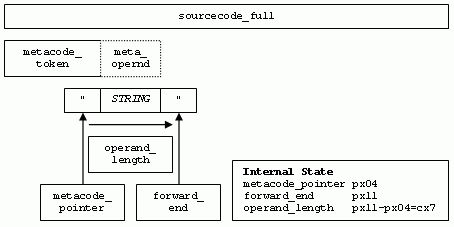 Variables and strings are usually involved within data exchange. This means strings or variables are written to other variables. This process is called assertion, assignment or cloning. They are tagged which the equal sign (=):
Software applications allow interactive and dynamic behavior. This is realized with control structures. All of them are identified as well. The occurence of one of the following keywords indicates such a control decision. These are linearized to for further analysis:
Last but not least comments are used within programming projects. The source code analysis of codEX is not interested in these detail (at least not in the current program specification). Therefore all lines which are indicated as comments are ignored:
Example of pre-compilation Regarding these definitons a simple translation from original PHP to intermediate MetaCode™ can be made. The example source code is the following:
As you can see this PHP code comes with one simple control structure. Depending on the given value in the variable $_GET['test'] another output is produced. If the input is set to 1, a static string is written. Otherwise a combination of static string and variable content is shown. The final translation to MetaCode™ looks like this:
This is the foundation for further token analysis. There are three columns used. In the first one the virtual addressing scheme is introduced. The addresses look something like xxx:yyy:zzz. The xxx declare the line within the original source code where the token was found. There might be several operation codes within the same line. The yyy declare the unique identification number of the identified token. And zzz declare the byte position of the token. This addressing scheme makes it possible to identify the tokens and to reuse their original addresses. For example the address 003:002:011 stands for source code line 3, token 2, byte 11. In the second row the central operation codes are shown. These are depending on the grammar of MetaCode™ itself. As discussed above the op code if is used to introduce the control structure for if decisions. And childopen declares an opening parenthesis. Some op codes use further operands which are shown optional in the third row. The first op code which such an extension can be found at 003:004:026. The varget defines a variable which is fetched from the HTTP GET request (e.g. http://192.168.0.1/forum.php?test=1). The name of this variable is proposed as test. Therefore the original introduction if this data within PHP looked like $_GET['test']. Another popular example is the op code for string which usually comes with the string content as operand (see 004:009:043 and 006:013:081). In the next step the identification of the operation codes is done. For example the dissection of all static strings and all the variables. Because of the normalization of the original source code this is very easy and comes with much more performance than further inspection of the source itself. Because MetaCode™ does not loose any details about the original source code, the desired level of source code analysis can be held. Bilbiography Aho, A.V., Sethi, R., Ullman, J.D. (1986), Compilers: Principles, Techniques, and Tools, Addison Wesley, ISBN-13 978-0201100884 Holzmann, G.J. (2003), Trends in Software Verification, Proceedings FME 2003: Formal Methods, International Symposium of Formal Methods Europe, Pisa, Italy, September 8814, 2003, http://spinroot.com/gerard/pdf/fme03.pdf Knuth, D.E. (1964), Backus Normal Form versus Backus Naur Form, Communications of the ACM 7 (December 1964), S. 735f. [back] |